状态:阅读中
标签:RAG
DOI:10.1145/3701716.3715240
注释:用知识图谱优化RAG
创建时间:2025年11月2日 23:34
目录
- 摘要
- 重要理论
摘要
近年来发展起来的检索增强生成(RAG)技术能够高效地构建领域特定应用。然而,它也存在一些局限性,例如向量相似度与知识推理相关性之间的差距,以及对知识逻辑(如数值、时间关系、专家规则等)的不敏感性,这些都阻碍了专业知识服务的有效性。本文提出了一种名为知识增强生成(KAG)的专业领域知识服务框架。KAG旨在解决上述挑战,充分利用知识图谱(KG)和向量检索的优势,并通过以下五个关键方面双向增强大型语言模型(LLM)和知识图谱,从而提升生成和推理性能:(1)LLM友好的知识表示;(2)知识图谱与原始数据块之间的相互索引;(3)逻辑形式引导的混合推理引擎;(4)知识与语义推理的对齐;(5)增强KAG的模型能力。我们将KAG与现有的RAG方法在多跳问答任务中进行了比较,发现KAG的性能显著优于现有方法,在2wiki和hotpotQA数据集上,F1分数分别提高了19.6%和33.5%。我们已成功将KAG应用于蚂蚁集团的两项专业知识问答任务,包括电子政务问答和电子健康问答,与RAG方法相比,在专业性方面取得了显著提升。
重要理论
RAG的两个缺陷
- RAG 通常依赖于文本或向量的相似性来检索参考信息,这可能导致搜索结果不完整或重复。
- 现实世界的流程常常涉及逻辑或数值推理,例如判断一组数据在时间序列中是增加还是减少,而语言模型使用的下一个词元预测机制在处理此类问题时仍存在不足。RAG 靠文本相似性检索,没法做 “数值计算””规则判断”(比如判断 160 是否符合 “一级高血压≥140” 的标准),只能靠 LLM “瞎猜”,很容易错。
KAG 的”整体框架”
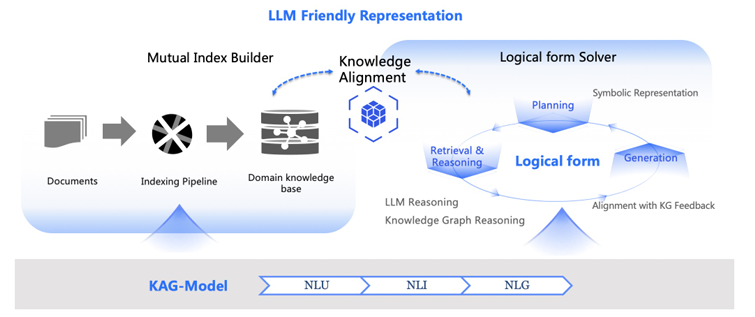
1️⃣ KAG-Builder(离线索引构建模块)
用于构建离线索引,把原始文献(比如医疗手册、政务文件)变成 “KG + 文本块 + 双向关联” 的知识单元与原始文本的双向关联(互索引)
- 第一步:语义分块(Semantic Chunking)
- 第二步:信息抽取 + 双向索引构建(Information Extraction & Mutual Index Builder)
- 信息抽取:使用 LLM 从每个 Chunk 中提取”实体、关系、事件”,形成SPO三元组,这些三元组构成图信息层(KG_fr)
- 双向关联:每个 SPO 三元组会关联”支撑它的 Chunk”
- 第三步:知识对齐(Knowledge Alignment)
- 实体消歧与融合:把有同义的实体进行合并,并补充”同义词”属性。
- 概念关联:把实体链接到 “概念树”。
- 语义关系补全:补充 SPO 中缺失的逻辑关系,特别是隐性关联。
2️⃣ KAG-Solver(在线问答求解模块)
用户问问题时,KAG-Solver 负责 “拆解问题→用 KG 推理→找文本细节→生成答案”。
- 第一步:生成逻辑形式(Logical Form Generation)
- 把模糊的自然语言编程”可执行的步骤”,避免传统 RAG “靠向量猜相关文本” 的盲目性。
- 第二步:混合推理引擎(Hybrid Reasoning Engine)
- KG检索(GraphRetrieval):首先在 KG Store 中查找,查看是否有现成的结构化答案。
- 文本检索(HybridRetrieval):如果 KG 中没有答案,调用Vector Store,根据向量检索相关的 Chunk.
- 第三步:反思与全局记忆(Reflection & Global Memory)
- 全局记忆(Global Memory):存储每一步的推理结果,避免重复计算。
- 反思判断:检查当前记忆是否能回答原始问题,按反思生成补充问题。多轮迭代直到全局记忆中的信息足够生成答案。
3️⃣ KAG-Model(模型能力增强层)
通过 NLU(自然语言理解)、NLI(自然语言推理)、NLG(自然语言生成)给 KAG-Builder 与 KAG-Solver 提供LLM的底层支撑,让 KAG 更会 “理解问题””推理知识””写专业答案”。
KAG 的核心技术
1️⃣ LLMFriSPG(LLM-Friendly SPG)
解决的痛点
传统KG使用结构化属性图(SPG、实体-关系-实体)来存储知识,其中有个问题:只有结构化关系,没有文本上下文和语义解释。LLM 看到的只有实体ID和关系标签,无法理解”这个实体是什么意思、来自哪段原文”,导致 KG 与 LLM脱节。
技术的三个核心升级
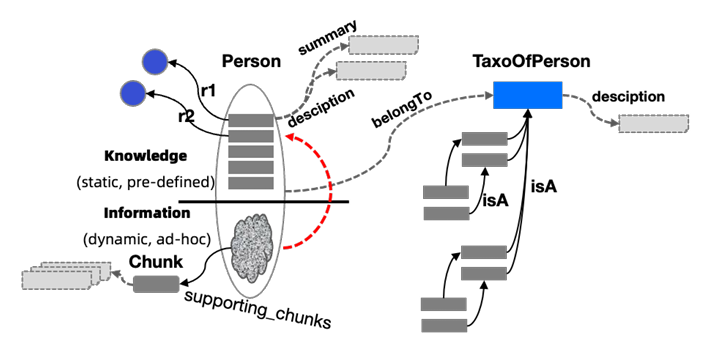
升级一:深度文本上下文感知 ——LLMFriSPG 通过新增三个核心属性,让实体 / 关系带上 “文本上下文,把 “结构化的 KG” 和 “非结构化的文本” 通过 “属性” 绑定,让 LLM 在处理 KG 时,能像读文本一样理解实体含义,而不是面对一堆无意义的标签。
- 支撑文本块(supporting_chunks):记录这个实体 / 关系来自哪段原始文本。
- 描述信息(description):分 “类型描述” 和 “实例描述”,解决 “LLM 不懂实体具体含义” 的问题。
- 类型描述(绑定到实体类型,如 “疾病”):比如给 “疾病” 这个 EntityType 加 description”人体在一定病因作用下,生理功能紊乱的状态”,是该类型的 “通用解释”;
- 实例描述(绑定到具体实体,如 “高血压”):加 description”常见慢性病,诊断标准为收缩压≥140mmHg 或舒张压≥90mmHg,常见症状有头晕、心悸”,是该实体的 “专属解释”。
- 摘要(summary):提炼实体 / 关系在原文中的核心信息,方便 LLM 快速获取关键逻辑,不用通读整个 Chunk。
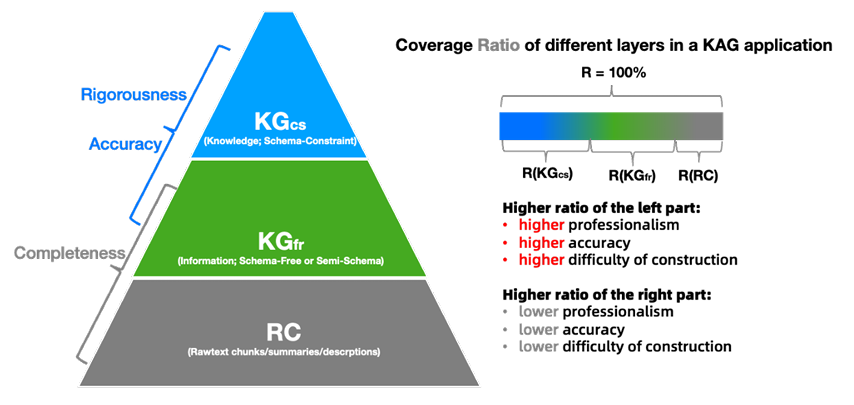
升级二:动态属性与知识分层 —— 将属性划分为动态的信息区和静态的知识区,让 KG “既能严谨又能灵活”,适配不同专业场景。并且通过 “DIKW 金字塔”,将知识分为三层,形成 “信息→知识” 的转化路径,确保 KG 的 “准确性” 和 “完整性” 兼顾。
- 动态属性
- 动态的信息区:对于信息检索场景需要灵活的动态属性(比如从文本中提取 “高血压患者应少吃盐”,不用提前定义 “饮食建议” 属性),确保知识完整。
- 静态的知识区:对于专业决策场景需要严格的 schema 约束(比如 “疾病” 必须有 “ICD 编码、诊断标准” 等固定属性),确保知识严谨;
- 知识分层
-
- RC 层(Raw Chunks,原始文本块层):最底层,是语义分块后的原始文本(如 “高血压饮食建议:每日盐摄入量≤5g”),信息最完整但最杂乱,没有结构化逻辑;
- KG_fr 层(Graph Information,图信息层):中间层,通过 OpenIE 从 RC 中提取的 SPO 三元组(如 <高血压,饮食建议,每日盐≤5g>),有结构化逻辑但可能有噪音(比如误提 “高血压→补钙” 的错误关系);
- KG_cs 层(Knowledge,知识层):最顶层,由专家标注或严格 schema 约束生成的 “标准知识”(如 < 高血压,诊断标准,收缩压≥140mmHg>),准确性最高、逻辑最严谨,但成本高、覆盖范围有限。
升级三:概念与实例分离 —— LLMFriSPG 通过 “概念图(Concept Graph)” 和 “belongTo 关系”,实现 “实例与概念的严格分离”,解决 “传统 RAG 无法做类别推理” 的问题。
LLMFriSPG的”核心价值”
总结下来,LLMFriSPG 不是 “推翻传统 KG”,而是 “给传统 KG 加适配 LLM 的’接口'”,它的三个升级点分别对应 KAG 的三大需求:
- 文本上下文感知→解决 “KG 与文本割裂”,为双向索引提供属性支撑;
- 动态属性与知识分层→解决 “专业场景严谨性与灵活性的矛盾”,让 KG 适配不同专业需求;
- 概念与实例分离→解决 “LLM 无法做类别推理”,为知识对齐和逻辑推理提供基础。
2️⃣ 双向索引(Mutual Indexing)
双向关联可以在后续 KAG-Solver 在回答问题时,既能用 KG 的结构化逻辑 “精准定位方向”,又能用文本块的细节 “补充完整信息”—— 这是 KAG 比传统 RAG 检索更准、比传统 KG 回答更细的关键。
双向索引的”两大核心组成”
4种核心数据结构 —— 定义”互查的内容”
| 数据结构 | 定义与作用 | 实例(住房公积金申请场景) |
|---|---|---|
| Shared Schemas | 在项目级别预定义为SPG类的粗粒度类型,是 KG 和文本块的 “统一分类标准”,确保两者类型一致(避免语义错位)。包括 EntityType(实体类型)、ConceptType(概念类型)、EventType(事件类型)。 | – EntityType:定义 “行政服务””Chunk”(文本块实体类型);- EventType:定义 “住房公积金申请事件”;- ConceptType:定义 “政务服务”(”行政服务” 的父概念)。 |
| Instance Graph | 存储所有实体 / 事件实例(包括 KG_cs 和 KG_fr 的实例),是双向关联的 “主体”—— 每个实例都通过 LLMFriSPG 的属性关联文本块。 | – KG_fr 实例:<住房公积金申请(事件实例),需要材料(关系),身份证(实体实例)>,其supporting_chunks属性设为 “Doc001-Para03-Chunk02″(对应 “申请材料” 文本块的 ID);- KG_cs 实例:<住房公积金申请(事件实例),办理时限(关系),3 个工作日(属性值)>,supporting_chunks关联 “Doc001-Para04-Chunk01″(”办理时限” 文本块)。 |
| Text Chunks | 特殊的 “Chunk 实体”(符合 LLMFriSPG 的 Chunk EntityType 定义),是文本块的 “结构化表示”—— 每个 Chunk 都带 “关联实例” 属性,反向关联 KG 实例。 | – Chunk ID:”Doc001-Para03-Chunk02″(由 “文档 ID + 段落码 + 块内序号” 构成,确保唯一且有序);- Chunk 属性:mainText=”申请住房公积金需提供本人身份证原件及复印件”,关联实例=”住房公积金申请事件(ID:E001)””身份证实体(ID:E002)”。 |
| Concept Graph | 由概念和概念关系构成(如 “住房公积金申请→行政服务→政务服务”),是 “知识对齐的核心”—— 辅助双向索引时的 “语义扩展互查”(比如查 “政务服务” 概念,能关联到所有属于该概念的实例及文本块)。 | – 概念关系:<住房公积金申请事件,belongTo,行政服务>、< 行政服务,isA,政务服务 >;- 作用:用户问 “政务服务的申请材料”,能通过概念关联找到 “住房公积金申请” 的文本块。 |
这 4 类结构的逻辑关系是:Shared Schemas 定 “分类标准”→Instance Graph 和 Text Chunks 是 “互查主体”→Concept Graph 做 “语义扩展”,确保双向索引既 “精准” 又 “全面”。
2种存储结构 —— 实现”互查的效率”
| 存储结构 | 存储内容 | 技术选型与作用 | 互查场景举例 |
|---|---|---|---|
| KG Store | 存储上述 4 类数据结构的 “结构化关系”(如 Instance Graph 的 SPO、Text Chunks 的 “关联实例” 属性、Concept Graph 的概念关系)。 | 用 LPG(带标签属性图)数据库,如 TuGraph、Neo4J—— 支持高效的 “图结构查询”(比如通过 SPARQL/SQL 查 “E001 事件关联的 Chunk ID”)。 | 已知 “住房公积金申请事件(E001)”,查它关联的 “申请材料” Chunk:在 KG Store 中执行查询 “MATCH (e:Event {id:’E001′})-[r:supporting_chunks]->(c:Chunk) RETURN c.id”,直接得到 Chunk ID “Doc001-Para03-Chunk02″。 |
| Vector Store | 存储 Text Chunks 的文本向量、Instance Graph 实体 / 事件的向量(如 “住房公积金申请” 的向量)、Concept Graph 概念的向量。 | 用向量存储引擎,如 ElasticSearch(支持稀疏向量)、Milvus(支持稠密向量)—— 支持 “语义相似检索”(比如查 “公积金申请要什么” 的向量,找到相关 Chunk)。 | 已知用户问 “公积金申请材料”,先在 Vector Store 中检索相似向量,找到 “Doc001-Para03-Chunk02″;再在 KG Store 中查该 Chunk 的 “关联实例”,确认它对应 “住房公积金申请事件”,排除 “社保申请” 等无关 Chunk。 |
双存储的协同逻辑是:Vector Store 负责 “语义召回”(快速找到可能相关的文本 / 实体),KG Store 负责 “结构化验证”(确认召回的内容是否真的和问题逻辑相关)
双向索引的 “构建流程”
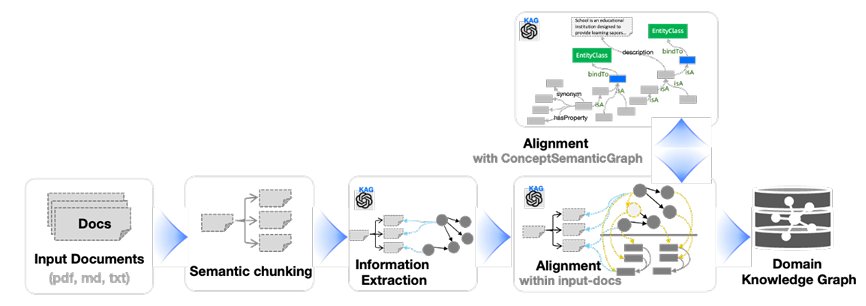
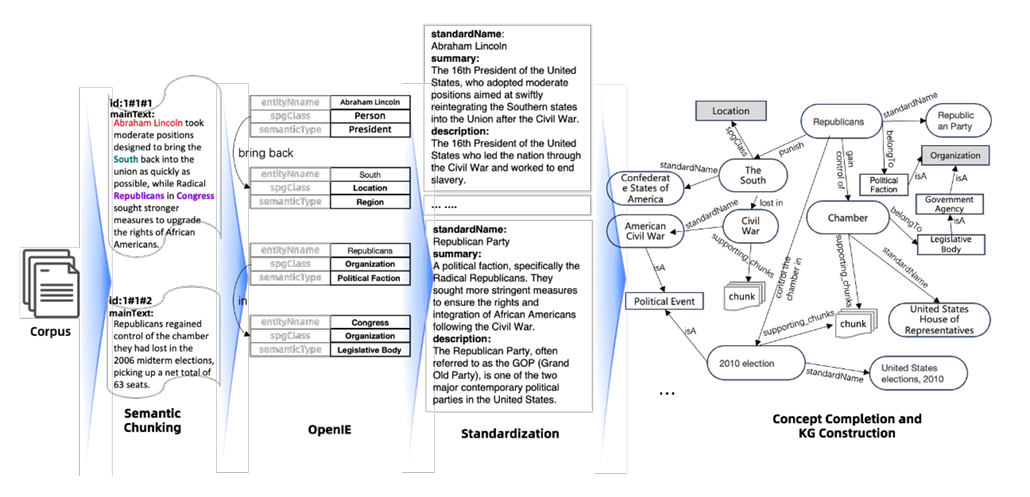
步骤一:语义分块(Semantic Chunking)—— 给文本块 “编唯一地址”
首先对原始文档做 “语义分块”,不是按固定字数切分,而是按 “主题连贯性” 拆成 Chunk,同时给每个 Chunk 编 “唯一 ID”(如 “Doc001-Para03-Chunk02″),确保后续能精准定位。
- 例:将《杭州住房公积金管理办法》拆成 “申请条件””所需材料””办理流程””杭州西湖受理点” 等 Chunk,每个 Chunk 的
mainText存原文,summary存 “杭州西湖公积金申请需身份证原件” 这类摘要。 - 关键:Chunk ID 的构成(文档 ID + 段落码 + 块内序号)确保 “内容相邻→ID 相邻”,比如 “办理流程” Chunk(Doc001-Para04-Chunk01)和 “受理点” Chunk(Doc001-Para05-Chunk01)在 ID 上能体现文档内的顺序,方便 LLM 理解上下文。
步骤二:信息抽取(Information Extraction) —— 从文本块中提 KG 实例,并关联 “来源地址”
用 LLM(如 GPT-3.5、DeepSeek)或微调模型 Hum,从每个 Chunk 中提取实体、事件、关系,构建 KG_fr 实例,同时给每个实例的supporting_chunks属性赋值为 “当前 Chunk 的 ID”—— 这是 “KG→文本块” 关联的关键一步。
- 例:从 “所需材料” Chunk(Doc001-Para03-Chunk02)中提取 SPO < 住房公积金申请(事件),需要材料(关系),身份证(实体)>,并将该事件实例的
supporting_chunks设为 “Doc001-Para03-Chunk02″。 - 额外优化:为每个实例生成
description(如 “身份证:本人有效期内原件”)、semanticType(如 “证件类材料”),这些属性会存在 KG Store 中,后续检索时能辅助过滤(比如排除 “临时身份证”)。
步骤三:领域知识注入(Domain Knowledge Injection) —— 给 KG_cs 实例关联文本块,补全 “严谨知识”
引入领域专家预定义的 KG_cs 实例(如 “住房公积金申请的办理时限 = 3 个工作日”),并找到原文中对应 “办理时限” 的 Chunk,将 KG_cs 实例的supporting_chunks关联到该 Chunk—— 确保 “严谨的结构化知识” 也有文本依据。
- 例:专家定义 <住房公积金申请(事件),办理时限(关系),3 个工作日(属性值)>,在原文中找到 “办理时限为 3 个工作日” 的 Chunk(Doc001-Para04-Chunk01),将该 KG_cs 实例的
supporting_chunks设为这个 Chunk ID。
步骤四:建立反向关联 —— 给文本块加 “关联实例” 属性,实现 “文本块→KG” 互查
在 Text Chunks 的属性中新增 “关联实例” 字段,记录 “从当前 Chunk 提取的所有 KG 实例 ID”—— 完成 “文本块→KG” 的反向关联。
- 例:给 “所需材料” Chunk(Doc001-Para03-Chunk02)的
关联实例属性赋值为 “事件 E001(住房公积金申请)、实体 E002(身份证)”,这样查这个 Chunk 时,能直接找到对应的 KG 实例。
双向索引的 “核心价值”:解决传统方案的 3 大痛点
- 解决 “RAG 检索盲目”:用 KG 逻辑缩小检索范围
传统 RAG 检索时,需要对所有文本块做向量比对,容易召回 “向量相似但逻辑无关” 的内容(比如把 “社保申请材料” 误判为 “公积金申请材料”)。而双向索引能先通过 KG 定位逻辑。
- 解决 “KG 回答空洞”:用文本块补充细节
传统 KG 只能返回 “需要身份证” 这样的结构化结论,但用户可能想知道 “是否需要复印件、是否需要本人到场” 等细节。双向索引能通过
supporting_chunks找到原文 Chunk,提取细节。 - 解决 “知识对齐困难”:用 Concept Graph 扩展互查范围
传统方案无法关联 “同类知识”(比如查 “政务服务材料”,无法关联到 “公积金申请材料”)。双向索引通过 Concept Graph 的概念关系,实现 “语义扩展互查”。
3️⃣ 知识对齐(Knowledge Alignment)
知识对齐是 KAG 框架中打通 “知识图谱构建” 与 “精准检索推理” 的关键桥梁,用明确的语义关系,把碎片化、模糊的知识串联成逻辑网络 —— 它解决了 “自动化构建的 KG 存在噪声、语义断裂,且与用户问题逻辑脱节” 的核心问题,是后续逻辑形式推理能精准执行的重要前提。
知识对齐的核心目标:解决 KG 与检索的 3 类”错位问题”
| 错位类型 | 具体问题 | 例子(医疗场景) |
|---|---|---|
| 1. 知识之间语义关系不匹配 | 正确答案与用户问题需要 “明确的语义关系”(如包含、因果、从属),但传统检索只靠向量相似性(无方向、无逻辑),导致检索不准。 | 用户问 “白内障患者适合的公共场所”,文献有 “博物馆为视障人士提供无障碍设施”—— 向量相似性低(文字不重叠),但 “白内障患者→视障人士” 是从属关系(isA),传统方法找不到这层关联。 |
| 2. 知识粒度错位 | 自动化提取(如 OpenIE)会产生 “同义 / 近义实体””粒度差异实体”,导致 KG 节点冗余、连通性差,检索召回不全。 | 提取出 “社保卡补办””社会保障卡 renewal””社保卡挂失后重办” 3 个实体 —— 实际是同一概念,但传统 KG 会当成 3 个独立节点,用户查 “社保卡补办” 时漏召回后两者。 |
| 3. 与领域知识结构不匹配 | 垂直领域(如医疗、政务)的知识需要 “系统性关联”(如 “疾病 – 症状 – 治疗” 的固定链路),但自动化 KG 常是碎片化的,缺乏专业结构。 | 医疗 KG 中只有 “高血压→头晕””高血压→收缩压≥140mmHg”,但缺 “头晕→需测血压” 的关联 —— 用户问 “头晕该做什么检查”,无法关联到 “测血压” 的专业建议。 |
知识对齐的 “工具“:6 种核心语义关系
| 语义关系 | 形式化表达 | 核心含义(方向 + 逻辑) | 领域案例 |
|---|---|---|---|
| 同义词关系 | <var1, synonym, var2> |
var1 与 var2 在同一语境下含义相同 / 相近(无方向,双向等价)。 | 政务场景:<社保卡补办,synonym, 社会保障卡 renewal>;医疗场景:< 心梗,synonym, 心肌梗死 >。 |
| 从属关系(isA) | <var1, isA, var2> |
var1 是 var2 的 “子类别”,var2 是 var1 的 “超类别”(有方向,从具体到抽象)。 | 医疗场景:<白内障患者,isA, 视障人士>;政务场景:< 住房公积金申请,isA, 行政服务 >。 |
| 部分 – 整体关系 | <var1, isPartOf, var2> |
var1 是 var2 的组成部分(有方向,从局部到整体)。 | 政务场景:<所需材料,isPartOf, 住房公积金申请流程>;医疗场景:< 心电图,isPartOf, 心脏检查 >。 |
| 包含关系 | <var1, contains, var2> |
var1 包含 var2(var2 是 var1 的子集,有方向)。 | 政务场景:<杭州政务服务,contains, 西湖区公积金办理>;医疗场景:< 慢性病,contains, 高血压 >。 |
| 实例 – 概念关系 | <var1, belongTo, var2> |
var1 是 var2 概念的 “具体实例”(连接实例与概念树,关键对齐手段)。 | 政务场景:<西湖区公积金办理点,belongTo, 政务服务网点>;医疗场景:< 张三的高血压病历,belongTo, 高血压病例 >。 |
| 因果关系 | <var1, causes, var2> |
var1 是 var2 的原因(有方向,从因到果)。 | 医疗场景:<高血压,causes, 左心室肥厚>;政务场景:< 材料不全,causes, 公积金申请驳回 >。 |
这些关系的核心价值:把 “模糊的自然语言关联” 变成 “可计算、可推理的符号逻辑”—— 比如用户问题与文献的关联,不再靠 “文字像不像”,而是靠 “是否存在上述语义关系”。
知识对齐的具体做法:离线增强索引(Enhance Indexing)+ 在线增强检索(Enhance Retrieval)
离线增强索引(KAG-Builder 阶段):在构建KG_cs(专家知识)和KG_fr(自动化提取知识)时,通过 4 种语义推理策略,提前修复 KG 的错位问题,为后续检索打基础。
| 对齐策略 | 具体操作(文献 2.4.1) | 效果(结合 Figure 9) |
|---|---|---|
| ① 知识实例消歧与融合 | 对重复 / 同义实例(如 “社保卡补办””社保 renewal”):1. 用实例的description和 1-hop 关系预测同义词集E_syn;2. 选定 1 个 “融合目标实例”(如 “社保卡补办”);3. 把E_syn的属性 / 关系合并到目标实例,删除冗余节点。 |
KG 节点冗余减少 40%+,同义实例被统一 —— 用户查 “社保 renewal” 时,能直接关联到 “社保卡补办” 的文本块(supporting_chunks)。 |
| ② 实例 – 概念关联 | 给每个实例(实体 / 事件)预测 “所属概念”,添加<实例, belongTo, 概念>三元组。 |
实例 “白内障”→添加<白内障, belongTo, 眼部疾病>;实例 “住房公积金申请”→添加<住房公积金申请, belongTo, 行政服务>—— 让实例归到 “概念树” 中,支持 “按类别检索”。 |
| ③ 概念关系补全 | 补全概念间的isA(从属)、contains(包含)关系,构建完整的 “概念层级”。 |
提取时只有 “白内障→眼部疾病”,补全后得到<眼部疾病, isA, 慢性病><慢性病, isA, 疾病>—— 形成 “疾病→慢性病→眼部疾病→白内障” 的完整链路,支持多跳推理。 |
| ④ 领域术语注入 | 提前注入领域标准术语(如医疗的 ICD 编码术语、政务的服务编码术语),让自动化提取的实例 “对齐到标准”。 | 医疗场景注入 “ICD-10 高血压编码 I10″,自动化提取的 “原发性高血压”→对齐到 “I10″,避免 “名称不同但编码相同” 的错位。 |
在线增强检索(KAG-Solver 阶段)
- 优先精准匹配,再语义推理 fallback
- 第一步:用逻辑形式中的 “类型、实体、关系”(如
<Event[办残疾证], location=杭州西湖>)在 KG 中做 “精准类型匹配 + 实体链接”—— 比如先找 “杭州西湖” 的 “办残疾证” 事件,直接定位关联文本块; - 第二步:若精准匹配失败(如 KG 中无 “杭州西湖办残疾证”,只有 “杭州政务服务→办残疾证”),触发语义推理:通过
<杭州西湖办残疾证, belongTo, 杭州政务服务>的关系,从 “杭州政务服务” 的节点出发,检索关联内容。
- 第一步:用逻辑形式中的 “类型、实体、关系”(如
- 用语义关系打通 “问题与文献” 的逻辑断层这是最核心的对齐场景 —— 用户问题与文献的文字不重叠,但存在语义关系,通过对齐实现 “跨文本关联”:
- 例子(文献 2.4.2):用户问 “白内障患者能去哪些公共场所?”(
q1),文献有 “博物馆为视障人士提供无障碍设施”(d2); - 对齐过程:先通过
belongTo关系确定 “白内障→眼部疾病”,再通过isA关系确定 “眼部疾病患者→视障人士”,最终关联到d2的文本块 —— 传统 RAG 因向量相似性低(”白内障”≠”视障”)无法检索,而 KAG 通过语义对齐成功命中。
- 例子(文献 2.4.2):用户问 “白内障患者能去哪些公共场所?”(
知识对齐的核心价值
- 对 KAG-Builder:让自动化构建的 KG 从 “碎片化、多噪声” 变成 “标准化、高连通” 的专业知识网络;
- 对 KAG-Solver:让用户问题与 KG / 文本块的关联,从 “靠文字相似” 变成 “靠逻辑关系”,彻底解决传统 RAG “检索盲目” 的问题。
4️⃣ 逻辑形式引导的混合推理引擎(Logical Form Solver)
逻辑形式(Logical Form, LF)的核心作用就是把自然语言问题翻译成 “机器能懂的、可分步执行的指令”
逻辑形式的核心构成:5 类基础函数
| 函数名称 | 核心功能 | 实例(对应问题:”威尼斯发生过多少次瘟疫?”) |
|---|---|---|
| Retrieval(检索) | 按 “实体 – 关系 – 属性” 精准查询 KG 或文本块,是最基础的函数(对应双向索引的 KG Store/Vector Store 调用)。 | 逻辑形式:Retrieval(s=o2:Place[威尼斯], p=plagueOccurrence, o=o3:Plague)→ 作用:从 KG 中查 “威尼斯” 的 “瘟疫发生” 相关记录,或从文本块中检索对应内容。 |
| Sort(排序) | 对检索结果按 “数值 / 时间” 排序(升序 min / 降序 max),支持取 Top N。 | 逻辑形式:Sort(A=瘟疫发生年份, direction=max, limit=1)→ 作用:找出威尼斯最近一次瘟疫的年份。 |
| Math(计算) | 对检索结果做数值运算(计数、求和、减法等,支持 LaTeX 语法)。 | 逻辑形式:math1=Math(count: ∥o3∥)→ 作用:统计 “威尼斯瘟疫” 实例(o3)的数量,得到瘟疫发生次数。 |
| Deduce(推理) | 判断两个结果的逻辑关系(蕴含、大于、等于等),解决 “是 / 否””包含 / 不包含” 类问题。 | 逻辑形式:Deduce(left=o1:Chunk[材料清单], right=身份证原件, op=entailment)→ 作用:判断 “申请材料 Chunk” 是否包含 “身份证原件”。 |
| Output(输出) | 把前面步骤的结果整合为最终答案,是推理的 “收尾函数”。 | 逻辑形式:Output(math1)→ 作用:输出 “瘟疫发生次数 = 22″。 |
关键特点:这些函数是 “可组合、可嵌套” 的 —— 复杂问题会拆解成 “多个函数的流水线”,比如 “比较两个导演的年龄” 会拆成 “Retrieval(查导演)→ Retrieval(查出生年份)→ Math(算年龄)→ Deduce(比较大小)→ Output(输出结果)”。
混合推理的完整执行流程
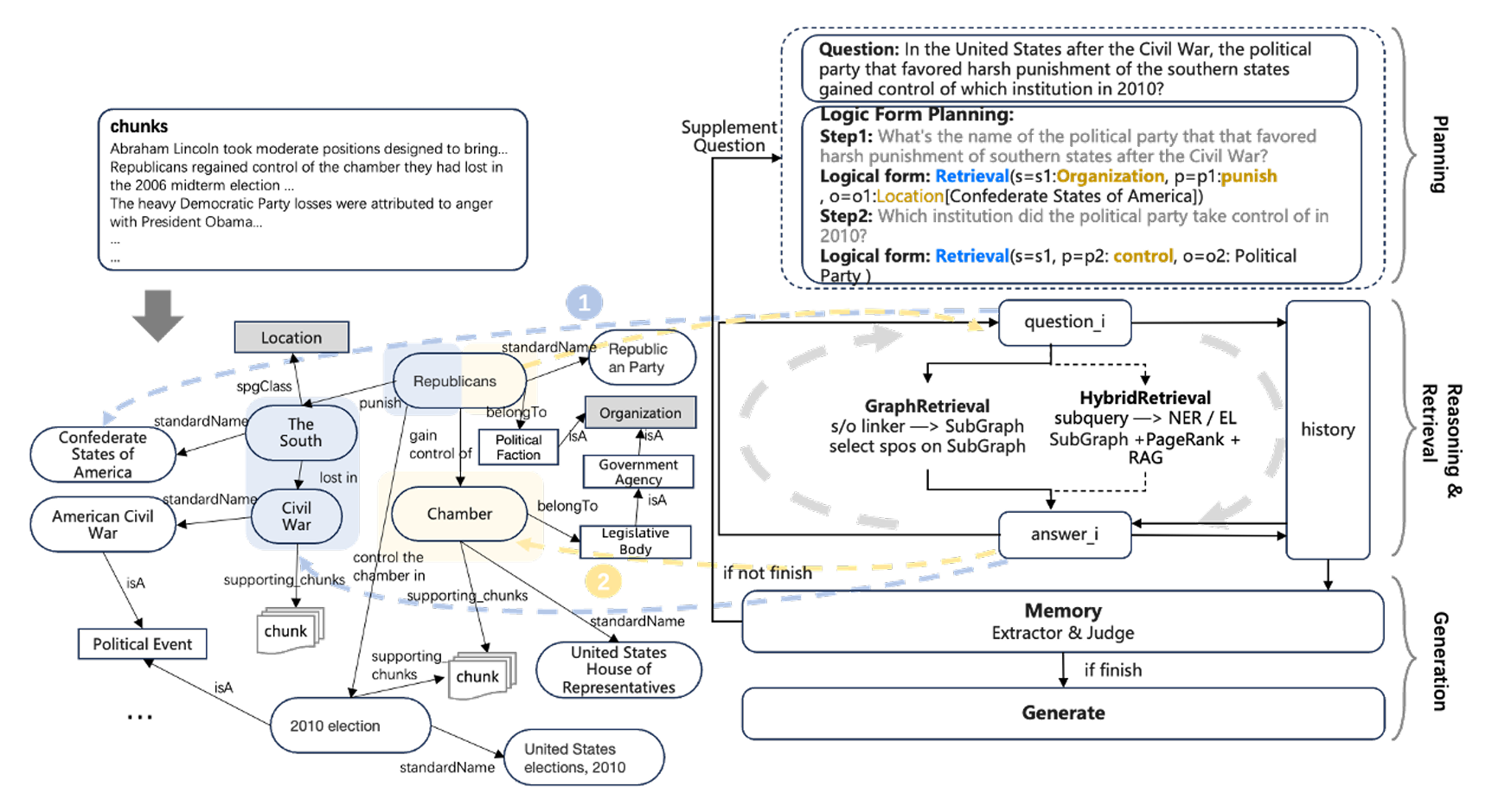
第一步:问题拆解(Planning)→ 生成逻辑形式列表(If_list)
- 引擎首先用 LLM(KAG-Model 的 NLU 能力)把原始问题拆成 “多个子问题”,每个子问题对应一个逻辑形式(lf),形成 lf_list。
- 子问题之间通过 “变量关联”(如 o1 是子问题 1 的结果,子问题 2 直接引用 o1),确保推理的连贯性 —— 这是处理 “多跳问题” 的核心。
第二步:执行推理(Reasoning & Retrieval)→ 调用 KG 和文本块
- 先查 KG Store(GraphRetrieval):用 Retrieval 函数精准查询 KG 中的 SPO 三元组,看是否有现成答案。
- 子问题 1 执行:查 KG 得到
<Concerto in C Major Op 3 6, composer, Antonio Vivaldi>,直接得到答案 o1=Antonio Vivaldi(无需查文本); - 子问题 2 执行:查 KG 未找到 “Antonio Vivaldi 的出生地”,触发下一步文本检索。
- 子问题 1 执行:查 KG 得到
- 再查 Vector Store(HybridRetrieval):如果 KG 无答案,调用双向索引的 Vector Store,根据 “子问题 + KG 检索结果” 检索相关文本块。
- 子问题 2 执行:用 “Antonio Vivaldi + birthPlace” 的向量检索文本块,找到 Doc2:”Antonio Lucio Vivaldi… Born in Venice”,得到答案 o2 = 威尼斯;
- 子问题 3 执行:查 KG 无 “威尼斯瘟疫次数”,检索文本块找到 Doc2:”威尼斯 1361-1528 年瘟疫 22 次”,通过 Math 函数计数得到 math1=22。
关键:混合推理的 “混合” 体现在 “KG 精准推理 + 文本细节补充”,既避免了传统 KG 的知识稀疏,又避免了传统 RAG 的检索盲目。
第三步:多轮反思(Reflection & Global Memory)→ 补充遗漏信息
- 全局记忆(Global Memory):存储每一步的推理结果,避免重复计算。
- 反思判断:检查当前记忆是否能回答原始问题,按反思生成补充问题。多轮迭代直到全局记忆中的信息足够生成答案。
第四步:答案生成(Answer Generation)→ 整合结果并追溯来源
最后,引擎调用 KAG-Model 的 NLG 能力,将全局记忆中的 “子问题答案 + KG / 文本来源” 整合为自然语言答案,并附带知识来源。
逻辑形式引擎的”核心优势”
- 多跳推理问题(需要跨知识源关联)
- 例子:”A 的父亲的出生地是哪里?”(需查 “A→父亲””父亲→出生地” 两跳);
- 传统 RAG:可能只检索到 “A 的父亲” 的文本,漏掉 “出生地” 关联;
- KAG:拆解为两个 Retrieval 函数,通过变量关联(o1 = 父亲,o2 = 出生地),逐步推理。
- 数值 / 逻辑推理问题(需要计算或逻辑判断)
- 例子:”2023 年某疾病发病率比 2022 年高多少?””找出同时含蔬菜和水果的图片”(Table 14 案例);
- 传统 RAG:无法直接做数值减法或 “与 / 或” 逻辑判断;
- KAG:用 Math 函数计算差值,用 Retrieval+Deduce 函数实现 “与 / 或” 逻辑(如 “先查含蔬菜的图片,再查其中含水果的”)。
- 模糊问题(需要精准定位核心需求)
- 例子:”杭州西湖办残疾证要什么材料?”(含地点、事件、核心需求);
- 传统 RAG:可能检索到 “其他区域办残疾证” 或 “西湖办其他证件” 的无关文本;
- KAG:拆解为
Retrieval(s=Event[办残疾证], p=support_chunks, o=Chunk, s.location=杭州西湖),通过逻辑形式的 “属性约束” 精准定位双向索引中的 Chunk。
5️⃣ 模型能力增强层(KAG-Model)
KAG-Model 通过优化大语言模型(LLM)的三大核心能力(NLU、NLI、NLG),为KAG-builder, KAG-Solver 提供 “精准理解、严谨推理、专业生成” 的底层支撑;同时还创新了 “单步推理(Onepass Inference)”,解决传统多模型 pipeline 的效率问题。
KAG-Model 的核心目标:从 “多模型拼凑” 到 “统一能力整合”
传统 RAG 系统的痛点是 “能力分散”—— 建索引用信息提取模型、检索用向量编码器、推理用逻辑模型、生成用文本模型,形成多个独立的 “小模型 pipeline”,带来两个致命问题:
- 级联损失(Cascading Loss):前一个模型的误差会传递到后一个(比如信息提取漏了 “疾病症状”,后续推理就无法关联治疗方案);
- 高复杂度与高成本:每个模型都要单独训练、部署,适配难度大,尤其在专业领域(如医疗)标注数据稀缺时,小模型效果差。
KAG-Model 的目标是用一个 “能力增强的统一 LLM”,整合所有需要的 NLP 能力—— 通过优化 LLM 的 NLU(理解)、NLI(推理)、NLG(生成),让它既能支撑 Builder 的 “索引构建”(如实体提取、语义分块),又能支撑 Solver 的 “问答推理”(如逻辑拆解、答案生成),同时减少级联损失和系统复杂度(Figure 7 直观展示了 “索引 / QA pipeline 与三大能力的对应关系”)
KAG-Model 的核心创新:三大能力增强策略
增强 NLU(Natural Language Understanding,自然语言理解)—— 支撑 “精准信息提取与问题拆解”
NLU 是 KAG 的 “理解核心”,负责 “从文本中提知识”(Builder 的信息提取)和 “把用户问题拆成可执行步骤”(Solver 的逻辑形式生成)。传统 LLM 在专业领域的 NLU 问题是 “领域适配差”(比如把医疗的 “并发症” 误判为 “病因”),KAG-Model 通过 三个”大规模指令重构” 解决。
| 策略名称 | 核心做法(文献 2.5.1) | 解决的痛点 |
|---|---|---|
| ① Label Bucketing(标签分桶) | 1. 避免 “标签共现过拟合”:每个训练样本只标注 1 个核心标签(如 “实体提取” 只标 “疾病”,不标 “症状”);2. 易混淆标签分组(如 “心梗” 和 “心绞痛” 放一个桶),让模型学差异。 | 传统模型学 “标签组合模式”(如 “疾病 + 症状” 总是一起出现),到新领域(如政务 “服务 + 材料”)就失效;分桶后模型能独立理解每个标签含义。 |
| ② 灵活输入输出格式 | 1. 输出支持 5 种格式(markdown、JSON、自然语言等);2. 输入允许 “文档片段””表格””KG 三元组” 等多样形式。 | 传统模型只适配固定格式(如 “输入 = 单句,输出 = 实体列表”),遇到专业文档(如医疗检查表、政务流程图)就无法处理。 |
| ③ 带任务指南的指令 | 1. 用 LLM 自反思生成 “任务描述”(如 “实体提取需包含疾病的 ICD 编码”);2. 指令中加入 “领域规则”(如 “政务服务提取需区分’办理流程’和’所需材料'”)。 | 传统模型靠 “题海战术” 学任务,不懂 “为什么这么做”(如提取 “姓名” 时不知道是否要包含 “职务”);带指南的指令让模型像 “专业标注员” 一样理解任务要求。 |
增强 NLI(Natural Language Inference,自然语言推理)—— 支撑 “知识对齐与逻辑推理”
NLI 是 KAG 的 “推理核心”,负责判断 “两个文本 / 实体的语义关系”(如 “白内障” 是否属于 “视障人士”、”申请材料” 是否包含 “身份证”),这是知识对齐和逻辑形式推理的基础。
- (1)构建 “领域概念知识库”
- 做法:收集 8000 + 跨领域概念(如医疗的 “疾病 – 症状”、政务的 “行政服务 – 材料”),标注文献 2.4 定义的 “六类语义关系”(synonym、isA、contains 等),形成 “概念 – 关系” 训练集;
- 目的:让 LLM 学习 “专业领域的语义逻辑”,而非通用常识。比如医疗领域,模型能理解 “心梗 isA 冠心病””冠心病 contains 心梗 / 心绞痛”,而不是只知道 “心梗和冠心病都和心脏有关”。
- (2)设计 “六类语义推理指令”
- 做法:针对每类语义关系,生成 “指令 – 示例” 对,让 LLM 通过 “指令微调(SFT)” 学会判断关系。例如:
- 指令:”判断 < var1, var2> 是否为 isA 关系,var1 = 白内障,var2 = 视障人士”;
- 示例:”答案:是,因为白内障会导致视力障碍,白内障患者属于视障人士范畴”;
- 做法:针对每类语义关系,生成 “指令 – 示例” 对,让 LLM 通过 “指令微调(SFT)” 学会判断关系。例如:
增强 NLG(Natural Language Generation,自然语言生成)—— 支撑 “专业、无幻觉的答案生成”
NLG 负责 “把推理结果整合成专业答案”(如医疗的 “指标解读”、政务的 “流程说明”)。传统 LLM 的 NLG 问题是 “领域脱节”(生成的答案逻辑混乱、术语错误)和 “幻觉”(编造不存在的医疗建议),KAG-Model 通过 “K-LoRA” 和 “AKGF” 两种轻量微调方法解决
- K-LoRA:让模型 “懂 KG 格式、会领域表达”
- 核心思路:知识生成是 “知识提取的逆过程”—— 既然能从文本中提 KG 三元组(如 < 高血压,症状,头晕 >),就能让模型从三元组反向生成文本(如 “高血压的常见症状包括头晕”),通过这种 “反向学习” 让模型熟悉 KG 逻辑和领域风格。
- 做法:
- 构建 “triples-to-text” 训练集:用 Builder 提取的 KG 三元组(如医疗的 < 心梗,治疗,溶栓 >、政务的 < 公积金申请,材料,身份证 >),让 LLM 生成 “符合领域风格的文本”;
- 用 LoRA(轻量微调)训练:只冻结 LLM 的大部分参数,只微调少量适配层,兼顾 “效果” 和 “效率”(训练成本比全量微调低 80%)。
- AKGF(Alignment with KG Feedback):用 KG 做 “自动纠错”,减少幻觉
- 核心思路:借鉴 RLHF(人类反馈强化学习),但用 “KG 替代人类” 做自动反馈 —— 生成多个答案后,用 KG 判断 “答案是否符合事实”,给正确答案高奖励,引导模型优化。
- 做法:
- 多答案生成:对同一个问题(如 “高血压的治疗方案”),用不同输入格式生成 3-5 个答案;
- KG 评分:对比每个答案与 KG 的 “SPO 匹配数”(rspo)和 “实体匹配数”(re),用公式计算奖励:
reward = log(rspo + α×re)(α 是超参数,平衡 SPO 和实体); - 强化学习:用奖励信号微调模型,让模型更倾向于生成 “KG 验证为真” 的答案。
KAG-Model 的效率创新:Onepass Inference(单步推理)
- 词汇表扩展:在 LLM 的原始词汇表中加入 “特殊检索 token”(如<Retrieve>、<Chunk123>),这些 token 专门负责 “检索任务”;
- 训练方式:
- 检索 token:通过 “对比学习” 微调 —— 让模型生成的<Retrieve>token 能精准对应 “需要检索的文本块 ID”(如<Chunk123>对应 “高血压治疗” 的文本块);
- 生成 token:按传统语言模型目标训练,负责将检索到的内容整合成答案;
- 推理时:模型 autoregressive(自回归)生成时,遇到需要检索的步骤会自动生成<Retrieve>token 和对应的文本块 ID,直接从向量库调取内容,无需额外调用检索器 —— 实现 “生成→检索→生成” 的单步完成
KAG-Model 的核心价值总结
KAG-Model 不是 “全新的 LLM”,而是 “为专业领域知识服务定制的 LLM 增强方案”,它的价值体现在三个 “支撑”:
- 支撑 Builder 的 “高质量索引构建”:通过增强的 NLU 精准提取实体 / 关系,减少索引噪声;
- 支撑 Solver 的 “精准推理与生成”:通过增强的 NLI 完成知识对齐和逻辑判断,通过增强的 NLG 生成专业无幻觉的答案;
- 支撑系统的 “高效率与低复杂度”:通过 Onepass Inference 整合检索与生成,减少级联损失和部署成本。
KAG 的应用
应用场景
电子政务(E-Government)、电子医疗(E-Health)
两个应用场景的共性:KAG 落地的核心逻辑
不管是政务还是医疗,KAG 能成功落地,本质是抓住了 “专业领域知识服务” 的 3 个核心需求:
- 需求 1:知识要 “准” → 靠 “知识对齐(2.4)+ KAG-Model 的 NLI(推理验证)” 解决,避免术语混淆、逻辑错误;
- 需求 2:答案要 “全” → 靠 “双向索引(2.2)+ LLMFriSPG(KG 与 Chunk 互查)” 解决,不遗漏关键信息(如政务材料、医疗注意事项);
- 需求 3:生成要 “专业” → 靠 “KAG-Model 的 NLG(领域适配生成)+ 专家规则(如医疗 DSL)” 解决,避免口语化、不严谨。
KAG 的局限性
- 多 LLM 调用导致 “高计算 / 经济开销”
- 用 “小模型替代大模型”:把简单任务(如实体识别、关系召回)交给领域适配的小模型(如医疗小模型、政务小模型),只让大模型处理复杂任务(如逻辑拆解);
- 减少中间 token:优化逻辑形式的表达,比如用更简洁的函数符号(如 “R” 代替 “Retrieval”),减少不必要的辅助文本。
- 复杂问题的 “拆解与规划能力” 不足
- 预训练 + 微调优化:用 “复杂问题拆解数据集”(如多轮推理 QA)预训练 LLM,让它学会 “转换推理维度”;
- 引入 “规划反馈”:用 KAG 的推理结果反向修正拆解逻辑(比如发现 “查年龄” 得不到答案,自动切换到 “查出生年份”)。
- OpenIE 带来的 “知识对齐挑战”
- 多模态信息提取:结合文档结构(如医疗手册的 “标题→子标题”)辅助 OpenIE,提升复杂知识的提取准确率;
- 半自动化标注:先让 OpenIE 生成初稿,再让专家 “轻量修正”(如只改错关系,不改对的),降低人工成本;
- 知识冲突检测:在 KG 中加入 “冲突检测规则”(如 “同一材料不能既需要又不需要”),自动修正多轮提取的不一致。
个人理解
技术原理上 —— 从语义相似到逻辑认知的范式转变
- 打破 RAG 的“向量迷信”:
- 思考: 传统的 RAG 过于依赖 Embedding 的向量相似度。但这篇论文让我意识到,“长得像”不等于“逻辑相关”。例如,“高血压”和“低血压”在向量空间可能很近,但在医疗推理中是完全相反的逻辑。
- 启发: KAG 的核心创新在于引入了逻辑形式(Logical Form)和神经符号推理 。它实际上是在 LLM 的“感性直觉”(文本生成)之上,强加了一层 KG 的“理性逻辑”(符号推理)。未来的 RAG 系统不应只是 Search Engine(搜索引擎),而应该是 Reasoning Engine(推理引擎)。
- 双向索引(Mutual Indexing)的桥梁作用:
- 思考: 以前做 KBQA(知识库问答)和 RAG 是割裂的,要么查图,要么查文。KAG 提出的
Mutual Indexing让图谱节点(Entity)和非结构化文本块(Chunk)互为索引。 - 启发: 这解决了一个痛点:KG 往往太稀疏(缺少细节),而文本太杂乱(缺少结构)。这种“图文互查”的结构,可能是未来构建高质量垂直领域知识库的标准范式。
- 思考: 以前做 KBQA(知识库问答)和 RAG 是割裂的,要么查图,要么查文。KAG 提出的
技术局限性上 —— 精度与效率的博弈 (The Trade-off)
- “慢思考”带来的系统延迟:
- 思考: 论文虽然效果很好,但其 Pipeline 非常长:
规划(Planning) -> 图检索 -> 文本检索 -> 推理 -> 反思。这是一种典型的 慢思考 模式。 - 启发: 在工业界落地时,延时(Latency) 是致命伤。论文提到的
Onepass Inference虽然试图用单步推理来解决这个问题,但我认为,如何实现“动态路由”才是关键——即简单问题走传统 RAG(快),复杂逻辑问题才走 KAG(慢),而不是“杀鸡用牛刀”。
- 思考: 论文虽然效果很好,但其 Pipeline 非常长:
- OpenIE 的“噪声放大器”风险:
- 思考: KAG 依赖 OpenIE(开放信息抽取)来自动化构建图谱 。虽然论文提到了“知识对齐”来消除歧义 ,但如果底层的抽取模型(Extraction Model)本身质量不高,会产生大量垃圾三元组。
- 启发: 这就是所谓的“级联误差”(Cascading Loss)。在实际复现时,我们可能不能盲目信任 OpenIE,对于核心领域知识,依然需要高质量的 Schema 约束 甚至人工审核,而不是完全自动化。
- 多 LLM 调用导致 “高计算 / 经济开销”:
- 思考:这是一个非常现实的瓶颈。正如论文局限性章节所言,KAG 框架在构建和推理阶段都需要频繁调用 LLM(例如规划、实体识别、关系提取全靠大模型)。
- 启发:
- 经济账: 这意味着 KAG 的每一次回答背后,可能伴随着大量的中间 Token 消耗(Intermediate Tokens),这些 Token 用户看不见,但由于逻辑拆解和符号化表达,生成量甚至可能达到原始问题的两倍。这在商业落地时会带来巨大的成本压力。
- 解决思路: 论文提到未来可以用**小模型(Small Models)**替代大模型来处理实体识别等特定任务。我认为这指明了一个方向:未来的系统不应该是“一个超大模型做所有事”,而应该是“大模型负责逻辑规划(Brain) + 多个专用小模型负责执行(Hands)”的协作模式。
技术落地上 —— 数据治理优于模型调优
- 垂直领域的“确定性”需求:
- 思考: 论文选择了“电子政务”和“电子医疗”两个场景 ,这非常有代表性。因为在这两个领域,用户不能容忍 LLM 的“幻觉”。KAG 通过 DSL(领域特定语言)和专家规则 ,把“概率生成”变成了“确定性计算”(如判断血压 160 是否属于高血压 )。
- 启发: 这告诉我,做垂直领域大模型,上限看 LLM 的智商,下限看 KG 的约束。单纯微调 LLM 很难解决严谨性问题,必须引入符号化的知识约束。
- 从 Model-Centric 到 Data-Centric:
- 思考: KAG 框架中,很大一部分工作量在于
KAG-Builder(建索引、对齐、分层)。 - 启发: 这再次印证了“数据为王”。KAG 本质上是一套高级的数据治理和组织方案。对于我们研究生阶段的科研,如果没资源训练大模型,不如把精力花在如何设计更好的 Knowledge Representation(知识表示)上,这同样能带来巨大的性能提升。
- 思考: KAG 框架中,很大一部分工作量在于

写的还行